Research Works of Participants
- Anton Balucha: Support of Retrieving Social and Family Relationships
- Michal Barla: Combining Traditional and Social-based User Modelling
- Peter Bartalos: Scalable Semantic Web Service Composition Approach
- Marko Divéky: Generating Dynamic Interactive Stories
- Pavol Fábik: Conference Bookmarking
- Michal Holub: Model Based Improvement of Website Structure
- Ján Hudek: Collaborative Concept Map Creator Web Portal
- Ivan Kišac: Accessing Information on the Social Adaptive Web
- Michal Kompan: Personalised Recommendation of Potential Interesting Articles
- Katarína Kostková: Identifying an Individual Person in Large Information Spaces by Leveraging Social Relationships
- Tomáš Kramár: Leveraging Social Networks in Navigation Recommendation
- Martin Labaj, Peter Líška, Michal Lohnický, Danel Švoňava: Novel Approach to Information Presentation Employing a Game
- Michal Masliš: Focused Web Crawler
- Vladimír Mihál: Annotation of Programs and Texts about Programming
- Pavel Michlík: Solved Exercises in Adaptive Educational Web-based System
- Martin Nepšinský: Creating On-the-Fly Documents for Adaptive Applications
- Michal Oláh: Recommendations in Multidimensional Data
- Ľuboš Omelina: Extracting information from Web Pages based on Graph Models
- Adrián Rakovský: Web Browsing based on Graph Visualization
- Jakub Šimko: Graphic Tools in Service of Exploratory Search
- Marián Šimko: Improving Search Results with Lightweight Semantic Search
- Ján Suchal: Extracting Information from Web Pages based on Graph Models
- Jozej Tomek: Virtual Communities Identification for Adaptive Web Systems
- Jozef Tvarožek: Socially-Intelligent Tutoring and Collaboration
- Michal Tvarožek: Intuitive Exploratory Search
- Peter Vojtek: Tax Fraud Detection with Relational Classifier
- Dušan Zeleník: Searching Similarities and Clustering
-
Support of Retrieving Social and Family Relationships
Anton Balucha
bachelor study, supervised by Mária BielikováThe Internet contains many various pages, which can be useful for searching relatives and relationships. Very interesting and valuable sources of personal information are gravestones. They are containing information about persons, who are buried in a certain place, their date of birth and death. Many times these gravestones contain photography of these persons. Way of getting information from gravestones is called pasportisation. It is a geodetic digital describing of cemetery, gravestones, trees, interesting points, collecting information about cemetery and its history and photos. The result of this research is digital map of cemetery, database of death people and photos of gravestones.
Main goal of our work is to create a social network by using information from gravestones. When we create social network of deceased, we use information from pasportised gravestones. Gravestones are holding information, which are split into two types:
- direct information – they are information acquired directly from gravestone.
- indirect information – they are information about deceased, which are not holding data about life if deceased, but indirectly help us to create social network.
These sources provide various data, which has various roles in process of creation social network from deceased.
Ways and methods of creation social network consist of some elementary activity, which are connected to each other and creates family relationships. One family is created from information about gravestone and these families are subsequently connected together.
Instances of persons have attributes, which are used to creation of social network. We can identify presented relationships between two persons based on evaluating personal these characteristics.
-
Combining Traditional and Social-based User Modelling
Michal Barla
doctoral study, supervised by Mária BielikováThe project is dealing with creation and maintenance of user model and social relationships for adaptive web-based systems, focusing on connecting the traditional user modeling with social approaches, which are nowadays very popular.
One of the problems we are aware of in the traditional user modelling is a cold-start problem, when the system cannot provide any meaningful personalization to a new user, for who it does not have any information stored in his or her user model yet. However, such a new user is probably the one which deserves the most some help and guidance provided by the system, in order to get more familiar with its interface, provided functionality and the presented information space itself.
Or goal is to contribute to the cold-start problem solving by leveraging social relationships between a new user of the system and other, already present users. The approach is motivated by social behavior, which is inherent to most of human beings. More precisely, the initial estimate of user characteristics is acquired as a weighted combination of characteristics other users interconnected with various types of relationships, acquired from various sources as well as based on common navigational patterns of users. The advantage of such approach is that it produces the standard user model, which can be maintained by well-established approaches to user modeling and which can be easily used by classical personalization and adaptation techniques.
We plan to evaluate our method in a domain of information research, such as searching for documents in the open information spaces as the web is or in closed but vast information spaces like digital libraries. We use rather simple keyword-based user model representation. More, we acquire various relationships between tags by analysing folksonomies and employing linguistic knowledge from Wordnet in order to compare particular user characteristics or even whole user models.
Our evaluation platform is an adaptive proxy server capable to personalize either user requests (e.g., disambiguate the search keywords) or responses sent from particular web server (e.g., annotate or re-rank search results).
-
Scalable Semantic Web Service Composition Approach
Peter Bartalos
doctoral study, supervised by Mária BielikováSemantic web services present a topical research area aimed at exploiting semantic annotation of web service descriptions. One of the most studied topics in this area is the automation of the semantic web service composition aiming at arranging several services into one complex service to be able to realize more complicated workflows.
Our approach to semantic web service composition deals with a semantic description of pre/postconditions of web services and a goal we intend to achieve using the service composition. The main contribution is related to the composition algorithm taking into consideration the pre/postconditions. Considering pre/postconditions we find all possible branches of the workflow leading to the specified goal. The conditions affecting which branch will be taken during the execution are created automatically. The algorithm exploits data structures created during preprocessing. We perform a huge amount of computation in the pre-processing phase, which allows for fast response to user queries. Moreover, already during composition, we automatically identify data to be presumably used as inputs during execution. To do this, data available in the operating environment (dedicated data repository) or values from the given goal are used. This way we prepare the workflow for execution. In the whole process we exploit the semantics related to the data.
To express the semantic of the web services we use OWL-S. The pre/postconditions are described using SWRL (Semantic Web Rule Language) and its extension. This way we are able to express more complex statements. The statements represent predicates which are combined using first order logic operators such as negation, conjunction and disjunction. The pre/postconditions are considered during the web service chaining. To chain two services, it is necessary that the postcondition of the ancestor service satisfies the precondition of the successor service.
Our future work deals with the exploitation of the composition approach in the context of dynamic business process creation. We also design the architecture of a system providing composition capabilities for the business applications.
-
Generating Dynamic Interactive Stories
Marko Divéky
master study, supervised by Mária BielikováStories and the art of storytelling have played an inevitable role in our lives ever since the earliest days of language. In today’s modern times, the educational potential of stories and storytelling is widely utilized in many different areas. Interactive storytelling is a new area of research in the field of artificial intelligence that focuses on combining conventional stories with interactivity, resulting in immersing the reader inside the story by letting him shape the storyline in any desired direction through committing narrative actions. Despite the large amount of work that has already been done in this field, there have been only a few working solutions that found practical use other than being a proof-of-concept demonstrations.
The goal of this work is to propose and evaluate an innovative approach to interactive storytelling that utilizes computer role-playing games as the storytelling medium. The proposed concept can be broken down into the following three layers:
- Character Behaviour Layer generates goals of all in-game characters, including the player, according to interpersonal relationships and behavioural patterns.
- Action Planning Layer utilizes the Hierarchical Task Network (HTN) planning formalism and transforms all characters’ goals into plans consisting of actions visualizable and executable by the Visualization Layer.
- Visualization Layer uses the concept of computer role-playing games as the visualization and storytelling medium, formalized into a set of actions that each in-game character (including the player) is able to commit inside the game world.
A prototype of the proposed concept is to be evaluated, both formally and empirically, on an example storyworld in the domain of teaching the history of computing and programming basics. Formal evaluation consists of analysing the correlation between the number of rules and the number of possible story variations that can be generated according to these rules. Empirical evaluation of the prototype consists of test players filling out feedback questionnaires with a set of simple questions regarding various aspects of the generated interactive stories.
-
Conference Bookmarking
Pavol Fábik
master study, supervised by Mária BielikováConferences are crucial in the professional life of academics. They provide a platform for them to present the results of their research, learn from their colleagues, and network. Therefore, academics need to find the conferences that may help further their careers.
A few systems such as WikiCFP (http://wikicfp.com) or EventSeer, (http://http://eventseer.net) are helpful in that they provide large databases of conferences from which users can pick and create their personal list of conferences. In those systems, however, it is up to the user to create his or her own list, and to organize the various conferences. It is also left to users to enlarge those databases. They can do so manually by filling in an online form. These systems could be dramatically enhanced if academics where offered suggestions as to conferences that might interest them in based on their past selections and ratings. Such automatically generated personalized lists of conferences would spare hours of search to academics as well as ensure that they will not miss a conference opportunity because they did not find out about it.
The main objective of my project is to put in place the processes that will allow these personalized suggestions to be generated. Conference bookmarking provides a solution for inserting and sharing information about conferences based on social bookmarking. Users, documents (conference websites), keywords and relationships between them are the backbone of social bookmarking. The important processes which needed to be conceived and developed are:
- Creating personal lists of conferences based on users interests.
- Automatic inserting new conferences based on the conference list analysis from different sources (currently we would like to use DBworld server (http://www.cs.wisc.edu/dbworld/browse.html)
- Conference bookmarks recommendation will be based on
a. Keywords and user’s personal conference list and interests
b. Conference rating by users
-
Model Based Improvement of Website Structure
Michal Holub
master study, supervised by Mária BielikováThe amount of information on the web is expanding dramatically and it is being used by growing number of users. The information is made public on lots of websites. Many of these websites have inappropriate structure which prevents users from accessing information effectively. The key challenge is to improve the website’s structure so that it better suits the needs of its users.
In our work we focus on tracking the user’s behaviour on a website and finding models in it. Subsequently we try to develop a method to improve the website’s structure by personalising its content to the user who currently visits it. Our primary sources of data are the clickstreams produced by user when he browses the webpage. We intend to collect and analyse these clickstreams, and to search for user’s behavioural patterns. We can also collect data from other sources like server logs.
We mainly concentrate on extracting useful information from the user’s behaviour on a website. Our method of content personalisation is based on man in the middle principle. Software system that implements our method lies between user and web server. When the user requests a webpage from the server, the system captures the webpage and modifies it before displaying it to the user. It could for example replace the navigation menu with another one containing links which better suit user’s needs. Or it can rearrange the results provided by a search engine so that they reflect user’s preferences better. For this method to work efficiently we need accurate data. We need to precisely identify the session of a user and then to track as many of his actions on a website as possible. One of the possible solutions which we consider is to use a proxy server which is being built at our faculty. This server allows for capturing all requests and responses which go from users to web servers and vice versa. We can then implement our method of improving the website’s structure as a plug-in for this server.
The main contribution of using our method is that the user can get information of his interest quickly, without being overwhelmed by huge amount of ballast.
-
Collaborative Concept Map Creator Web Portal
Ján Hudek
bachelor study, supervised by Jozef TvarožekOur work consists of creating web based tool designed for building concept maps by multiple users. Concept maps represented as oriented graphs help understand complex domain areas. We explore ways to support users in creating concept maps collaboratively.
Concept maps contain of two basic elements. First is concept which is represented as a node. It is convention that one node should represent one concept of real world. The second element is edge. Edges are used to define relations between concepts that are linked by these edges. These relations have some basic attributes consist of a name and weight of the relation. Interesting and very important characteristic of the concept maps is the fact that the concepts differ in a number and weight of relations. This is very useful behaviour when we are trying to decide which concepts are more general. Globally if we look on the count and weight of the concept relations, the concept with the biggest multitude is probably the most general. This characteristic can be used in creating categories.
Building map for the purpose of collecting data can be very useful but concept maps can offer more. Concept map can assist as a toll for improving communication between people. Our work contains personal collaborative editor. Collaborative editor offer tools dedicated to creating concept map with limited count of users which are able to browse this map. This group of users is chosen by owner of the project. For example editor can help prevent communication problems between developers and customers caused by technical speech used by developers which can be hardly understood by ordinary people. Inaccurate formulation of requirements and unknown limitations of technologies by customers is also a big problem.
-
Accessing Information on Social Adaptive Web
Ivan Kišac
doctoral study, supervised by Mária BielikováThe web offers a huge amount of various documents in different formats. It’s very hard to find relevant information without being flooded by many irrelevant search results. The capability of automated document meaning recognition is restricted by the amount of provided machine treatable information that concerns the document content. The process of retrieving information, which will be relevant to user’s needs and interests, therefore may be difficult, tiring and time-consuming.
In the social network (or eventually in several ones, where the user was identified) the user’s profile can be created based on user’s characteristic. Systems can filter and recommend (prefer or suppress) incoming information according to created user profile. It is possible to notify about interesting people, articles and events related to user’s interests. The aim of this work is to create a classification method, which will help to evaluate the relevance of given object – person, event, article according to interest of the user. This method should decide whether to notify about existence of given object or not. It also helps in navigation in the space of given domain objects.
We are going to provide evaluation based on similarity, respectively conjunction of users’ profiles with focus on interests in profile, activity in related forums, etc. When evaluating articles we focus on authors, keywords and other available metadata.
Another considered approach will focus on temporal characteristics of relations in social networks and their progress or degradation. We will explore how these affect the relations in social network and the topology of the network.
-
Personalised Recommendation of Potential Interesting Articles
Michal Kompan
master study, supervised by Mária BielikováAmount of data accessible from whole internet is growing day by day. Number of people dependable on effective work with these data is enormous. Web content especially content of news portal is changing every day and value of this information is decreasing every minute. There is no chance to face up this problem without machine support based on recommendation systems. The main goal of our work is:
- analysing wide-used methods of similar text finding,
- categorization of these articles based on content,
- recommendation of these articles to the specific users.
Recommendation is based of user behaviour model and based on community behaviour model too. Information about users we gain without need of user logging to the system, based on various methods (e.g., using cookies). “Rating” of article, will be measured by positive or negative user evaluation, or based on time which is user reading article in proportion to length of text. Other potential method to find “type” of interesting articles, which we would like to study, is measuring of Flesch readability index. Promising idea is a recommendation of articles or types of articles in specific parts of the day. This idea is based on assumption, that user reads other type of articles when he came to work as for example in the afternoon or during lunch break.
Validation of proposed solution after precision research should be based on integration of methods into existing web news portal, or there is a possibility to create “gadgets-like” application distributed to users.
-
Identifying an Individual Person in Large Information Spaces by Leveraging Social Relationships
Katarína Kostková
master study, supervised by Michal BarlaSearching for information on a particular person in the vast information space of the Web became a non-trivial task. Our goal is to support this task by automatically deciding whether the information we have found on the Web, is relevant to the person we are interested in or not. Our approach is not limited to be used on the Web only, but can be applied to any large information space, which suffers by name variants and name disambiguation problems, such as DBLP database. The second, name disambiguation, problem is to correctly assign a publication, if there are several authors having the same name.
Employing additional, background knowledge of the domain, can solve both of the aforementioned problems. In our method the additional knowledge is represented by social networks, which identify person by his or her relationships with other individuals. To identify person we use comparison using semantically and syntactically based metrics.
Our method compares two persons, represented by their names, which are either namesakes or two variants of a name of the same person. As input we get a candidate web page of person we are looking for and his or her background knowledge. After process of identification, we get probability that web page is related to person we have been looking for.
In our case we will compare two names using weighted combination of Levenshtein distance and Jaro-Winkler distance. However, using syntactic comparison only does not lead to satisfactory results, with many name variants still unresolved. Therefore, we employ the semantic comparison techniques, which use additional information about compared persons, their social network.
-
Leveraging Social Networks in Navigation Recommendation
Tomáš Kramár
master study, supervised by Michal BarlaAssociation rules are nowadays commonly used to recommend navigation. From a set of all logged clicks, association rules are mined in a form: “If someone clicked on the link A, then, in 90% cases, he also clicked on link B”. Recommendations are then selected by matching the left parts of the rules. This type of recommendations however, does not take into account the context, or the interests of the user. If user searches using the keyword “latex”, which site should the system recommend? About typographical system, polymers or American city? If most of our users are technicians, the system would recommend typographical system to every chemist, until the chemists generate more clicks. In that case, the technicians would be “discriminated”. We can workaround these constraints, implied by the very nature of association rules by adding a context. It can be gained from social networks, which aggregate data and the connections between people.
The goal of the project is to analyse Web recommendation methods, design and experimentally evaluate various methods of navigation recommendation, which leverage social networks. The possible research directions are:
- Using classical association rules mined only from the part of the social network connected with the user
- Using inter-transactional, multidimensional rules, which enable to constraint the mined rules with multiple dimensions (clicks, time spent on site, network connections, etc.)
- Starting with classical association rules and adding context and generating new rules with an inference engine
-
inFUNmation – Novel Approach to Information Presentation Employing a Game
Martin Labaj, Peter Líška, Michal Lohnický, Danel Švoňava
bachelor study, supervised by Mária BielikováOur project proposes a solution for a problem constrained by Imagine Cup 2009 competition theme „Imagine a world where technology helps solve the toughest problems facing us today“ and by United Nations millennium goals – for example ending poverty and hunger, child and maternal health, HIV/AIDS fight. As a project theme we have chosen help for those who need it most – let it be people with insufficient resources to survive or ill people who need resources to get cured.
Our solution lies in indirect solving of the human problems and instead of direct help, we aim at improving the informedness of people who can help afterwards and do that more effectively than one focused solution. In order to do so we created a new approach to information presentation utilizing a game. User is in charge of vertices in a 3D structure – graph, where he is applying tools to satisfy various needs of the vertices. As this usage of the tools means costs, player is being pushed to use them effectively and in order to do so, he need to get to know all the information associated with the graph vertex – human stories, third world problems, etc. The aim of the game is to make the graph survive for longest time possible. This presentation concept can be also used wherever is information presentation concerned. It can be used for example to let an internet shop present its offer to the potential customers. The users will get to know the shop offerings better than in normal advertising because in order to play the game effectively, they need to explore the vertices and the information they contain.
After being informed about others’ problems user needs a way to help if he wants to. For this purpose we thought up a device called “Rounder” – a modification/change of the standard POS terminal processing credit/debit card payments in a shop. The Rounder allows customer to round off the amount being paid in progressively increasing steps as he presses a button. The extra funds arising from this activity will be sent to a charity or purpose chosen by the user and therefore he will have a option to help, at least financially, without most of the problems of more classical ways of donating.
-
Focused Web Crawler
Michal Masliš
bachelor study, supervised by Michal BarlaWeb Crawler is a software agent that systematic crawls web pages and saves their content on local disc. A focused crawler is a web crawler that attempts to download only web pages that are relevant to a pre-defined topic or set of topics. I describe various types of web crawlers:
- Restricting followed links
- Path-ascending crawling
- Crawling the deep Web
- Semantic web crawling
- Focused crawling
I describe knowledge representation for text classification, such decision trees, decision tables, Bayesian networks, naive Bayesian classification, TD-IDF. I design and implement a software device that can define and run focused web crawlers. I verify my solution with creating a focused web crawler that can download personal homepages. My program first analyses source code of two sets of pages – “homepages” and “not homepages”. It compares stems of words(stemming) from these two sets and learns from it, what is a personal homepage. Words belongs different important tags(title, strong, h1,…) has different coefficients. The set “not homepages” is important, program can determine, what word is usual in language. If my program will have knowledge database, then it can crawl over the internet and download personal homepages.
-
Solved Exercises in Adaptive Educational Web-based System
Pavel Michlík
master study, supervised by Mária BielikováWhen using an educational system that provides adaptive navigation, students will not access and study all the available learning materials in the same order. There is no predefined sequence of topics like chapters in a book. Therefore, the exercises which are provided to support educational texts and to allow the student to test his knowledge cannot be accessed in predefined order as well. That is because most exercises are related to more than one topic. In addition to that, the educational system can contain much more exercises than are necessary for the student to learn the topic. But when omitting some of the exercises, we need a mechanism which ensures that we do not leave out an important exercise which helps to explain some common misunderstanding.
The goal of this project is to design a method for selecting the next exercise for the student to solve. The method should consider:
- The student’s current knowledge of all related concepts (or topics) – this can be obtained from various sources: materials that he studied, test questions, previously accessed exercises and his feedback on them etc.
- The learning speed of the student – some students need more examples (exercises) to fully understand a concept than others. In addition to that, we will attempt to determine the student’s level of knowledge of the concept after studying the related text. Some students might want to go through trivial exercises first, so they check their understanding of the basic principles they have just learned from the text. Others do not need these simple exercises, most of which are identical or very similar to the examples that were used in the text. For these students the navigation should start at more difficult exercises.
- The feedback on the exercise that was provided by other students – the method should focus on exercises which are commonly misunderstood. These exercises probably explain aspects that are confusing or not entirely covered by the educational texts in the course.
The student’s feedback on the exercises will be provided by choosing one from following options:
- understood,
- understood after displaying the hint,
- understood after displaying the solution,
- not understood.
Peter Brusilovsky and his students designed an educational system with solved exercises and adaptive navigation. In their system, every exercise is displayed with a symbol which shows whether the student is ready to access the exercise (based on prerequisites at concept level) and the percentage of example code lines that were already explored by the student. The final choice of the example is done by the student himself. The system does not consider previous feedback on the exercise from other students, so it cannot identify exercises that are more important than others.
This project’s main contribution is an automated selection method that chooses one exercise which the student should examine next, considering previous feedback on the exercise and the student’s learning speed.
-
Annotation of Programs and Texts about Programming
Vladimír Mihál
bachelor study, supervised by Mária BielikováMain idea of this work is learning document content enrichment using adaptive annotation. Goal of notes added into a document is to simplify context related information search. We consider that a document extended by proper notes is more valuable for student in process of learning. There are two main aspects of on-line document annotation:
- Content explanation
- User communication and feedback
Purpose of content explanation notes is to give a student some useful hint when he gets lost while reading a learning text. These ‘hint notes’ are expected to provide desirable helping information needed for student to understand learning subject. Therefore student will not have to draw attention away from the learning text just to obtain necessary information from other information source. Second aspect is about integrating a communication within group of students with information source (for instance learning text) they discuss about. Students can discuss, argue, ask and come up with solutions directly within the learning document. It will tent to collection of all available information and grouping it by its context. Furthermore, rating of student notes by teacher (or eventually by other students) will serve as motivation to contribute to content creation and enrichment.
To proof concept of adaptive annotation we are developing an annotating system and we will test it within existing learning system FLIP. Evaluation will be done on a group of students using learning system to learn programming. We believe, that students from a group with notes enabled by default will not disable them and/or will learn subject better and faster.
-
Creating On-the-Fly Documents for Adaptive Applications
Martin Nepšinský
master study, supervised by Anton AndrejkoQuality and efficiency of content adaptation is one of the most important characteristics of adaptive educational systems. The more precisely is content adapted to the needs of the user, the more quickly can be achieved his/her objectives. Therefore this project focuses on personalization of content and presentation of documents according to the needs of particular users.
System’s content are educational courses, which are specified by generic documents in DocBook format and domain ontology. Every course consists of learning objects. Learning object can be understood as a logical section and each learning object may consist of text, pictures, links and other educational materials. Some parts of the learning object can be defined as fragments and fragment play a key role in adaptation process. The fragments in the domain model have mutual relationships.
Main aim of this project is adaptation model. Principle of the adaptation process lies in the gradual evaluation of individual parts of the generic learning materials and the subsequent composition of the output document only from the most reliable parts of the document. In typical use case, user chooses learning object, which he/she wants to study and application generates, on the fly, personalized document for chosen learning object. Gradual evaluation will calculate fitness, which determines fragment’s suitability to be in the output document. It means that fragments with a high value of fitness should be included in the output document and vice versa, fragments with low value of fitness are not very suitable for the output document. After composition of the final sequence of fragments, presentation of fragments is adjusted. According to the value of fitness fragment can be represented as: emphasized, normal, understated, stretchtext or link.
Secondary aim of this project is automation of creation of domain model, which will be based on analysis of keywords in fragments and relations between them. Future work will cover an experimental evaluation in domain of learning programming. Content of application will be part of the book Functional and logical programming.
-
Recommendations in Multidimensional Data
Michal Oláh
master study, supervised by Jan SuchalRecommender systems are becoming a standard part of internet shops and search engines. They use information gathered from users to predict future behaviour and to estimate user interests. One way the recommender systems work is based on representation of objects (users, products etc.) and their relations using graphs. These graphs are valued by various algorithms (e.g. PageRank, HITS) that increase the accuracy of a prediction. Current methods of recommendations and searching on the web work with a graph that has only one type of edges. Graphs with multiple types of edges can reveal new information not present when using prior methods. Using this approach enables search/recommendation much more effectively than it is currently possible.
The goal of the project is to create a recommender that uses multidimensional data to make its recommendation. It is also important to make it scalable to very large graphs with millions of edges using architectures such as MapReduce and Hadoop that make it much easier to scale to very large data sets. I plan to verify these methods on data sets coming from property portals. People tend to have very specialized requirements when buying real estate such as:
- Flat cannot be on the top/first floor
- Has to be located near the centre, but not in a “bad” neighbourhood
Based on the requests and multidimensional of the data I can make a very accurate recommender. Even though I used an example, the recommender should not be tied to one domain space and be usable in various domains.
-
Extracting Information from Web Pages Based on Graph Models
Ľuboš Omelina
master study, supervised by Michal BarlaAmount of information available on the Web is permanently increasing. It is becoming harder to find the most relevant information and to filter out the unwanted ones. Searching for information on the Web can be supported by techniques of information extraction when applied on semi-structured texts of web pages.
In our work, we are focused on applying information extraction techniques on the web pages using graph models and statistical modelling. It seems that statistical methods and graph models obtains significantly higher accuracy than human-tuned methods (i.e., regular expressions). We analysed the suitability of various graph models for this kind of problem and decided to use conditional random fields model. After this decision we devised several optimizations of the model in order to use it efficiently for the problem of extracting information from the web pages. We made a preliminary evaluation of the proposed solution on free texts describing the peoples’ interests and hobbies. We created a prototype and realized a small-scale experiment, which indicates a potential of the proposed information extraction method. In our experiment model extracted information as keywords and we obtained 84% precision.
We are aware, that the used dataset did not reflect the reality of the Web, which could bias significantly reported results. In our future work, we plan to perform an evaluation in the real conditions, which requires a training data set of a much higher quality. Therefore, we are deploying a specialized web-based editor, which allows for easy tagging of content on any web page and thus creating a training dataset. After we get more naturally dataset, we plan to focus more on the incorporation of additional information, resulting from the structured HTML representation of web pages.
-
Web Browsing Based on Graph Visualization
Adrián Rakovský
bachelor study, supervised by Michal TvarožekSince the Semantic Web is a relatively new field there are few generic ways how to present it. One possibility is to visualize it as a set of nodes and edges among them, because it is represented by RDF triples (subject, predicate, object), which are connected by edges and comprise a graph structure.
At present, there are some tools which deal with the visualisation of the Semantic Web as a graph, but unfortunately, most of them are dedicated to the Protégé platform and therefore are not usable on the Web. The result of this work is an application that not only supports Semantic Web visualisation but also its editing. Except of analysis of known solutions, there is also description of possible modern client web technologies that can be used in this solution and also usual ways of visualising graphs and their interaction.
We propose a method which constructs (a custom) graph from ontological information representation and presents it to users in a graphical user interface. All three components of RDF are displayed as nodes (predicates as well) and connected via oriented edges. Different types of nodes have different colours (predicates, objects, literals). Users have these options for interaction with the graph:
- Changeover to new graph (by entering a URI or selecting a node)
- Hiding predicates
- Zooming and panning
- Expanding graph to the next level
We also indent to include intuitive ontology editing functionality and more sophisticated zooming, because our current approach does not address the overlapping of nodes.
-
Graphic Tools in Service of Exploratory Search
Jakub Šimko
master study, supervised by Michal TvarožekOur aim is to research possibilities of utilizing the graphic visualization tools in faceted browsers and exploratory search domain. These tools mainly include visualizations of graph structures (such as ontologies representing conceptual schemata of search domains), which enable visual navigation across the information space and support the layout of search results based on hierarchy or semantic distance of given objects. Secondary to graph visualizations, our interest lays in exploring the potential of using other kinds of graphic visualization (gradient maps) or colour emphasising support respectively. We propose to improve search by more effective navigation in broader result sets, which often contain many irrelevant results (which the user must deal with), which make the search slower. Faceted browsers display results based on the settings of facets which represent additional criteria for further reduction and organisation of the set and are often represented as lists of options. The task for graph tools is to replace the classic list view. Graphs enable visibility of similar concepts (using connections or layout in two dimensions) and therefore reveal more relationships to users. Besides facets, a graph can also be used to represent the result set itself.
User is well concerned about what he wants, but also what he doesn’t want. We propose an option for user to manually remove an object or concept that he doesn’t want out of the graph. Removal or suppression of objects (concepts) similar to removed one may also follow. Removal action has also effect on other parts of the browser and has to be accompanied by strong feedback for user. Search history representation is other possible usage of graphs, particularly trees. In classic browser, history provides basic back step possibility, but is unclear when it comes to different search branches, when user is interested in more objects found. Continuously created, always visible tree of queries, visited objects or other actions performed during session, can give the user more clear view on his own work and results. In addition, history trees can be preserved as start points for later searches, or can be used by algorithms for user behaviour patterns seek.
Some objects are hard to find, and users often start to search them with no effective queries. After sequence of attempts they improve them and reach the demanded goal. We propose an approach for discovery mapping of “wrong queries” to “right objects” to create possible shortcuts for users. For this we need to determine start query of a session and what the result was. After multiple occurrences of such query-result couples, we can establish a mapping and start proposing shortcuts to “irrelevant” results. This is hardly possible in classic web search applications, because of lack of possibility of tracking user actions. Using applets with accent on session opening and closing makes that more possible.
Important challenge is to validate our approach. Because of need of user participation, this renders validation rather difficult. We plan to organize evaluation with group of common users with given search tasks. The search domain may be used both web and closed information space with more semantic intercepting structure (such as research publications base). We are still open to any other proposals for validation tests conceptions.
-
Improving Search Results with Lightweight Semantic Search
Marián Šimko
doctoral study, supervised by Mária BielikováTo satisfy user’s information needs, the most accurate results for entered search query need to be returned. Traditional approaches based on query and resource Bag-Of-Words model comparison are overcome. In order to yield better search results, the role of semantic search is increasing. However, the presence of semantic data is not common as much as it is needed for search improvement. Although there are initiatives to make resources on the Web semantically richer, it is demanding to appropriately describe (annotate) each single piece of resource manually. Furthermore, it is almost impossible to make it coherently. The current major problem of the semantic search is the lack of available semantics for the resources, especially when considering the search on the Web.
To overcome this drawback, we propose an approach leveraging lightweight semantics of resources. It relies on resource metadata – model representing resource content. It consists of interlinked concepts and relationships connecting concepts to resources (subjects of the search) or concepts themselves. Concepts feature domain knowledge elements (e.g. keywords or tags) related to the resource content (e.g. web pages or documents). Both resource-to-concept and concept-to-concept relationship types are weighted. Weights determine the degree of concept relatedness to resource or other concept, respectively. Interlinked concepts result in a structure resembling lightweight ontology thus allowing automated generation (we have already performed several experiments with promising results in e-learning domain).
Having domain model as described above, we examine the possibilities of search improvement. We propose two variants of so called concept scoring computation. With concept scoring we extend the baseline state-of-the-art approaches to query scoring computation expecting an improvement of the search. Utilizing metadata we are able to assign the query to particular topic (set of concepts) and yield more accurate search results with respect to related resources. Currently we are working on the evaluation of the proposed approach.
-
Improving Search in Multidimensional Data Using Graphs and Implicit Feedback
Ján Suchal
doctoral study, supervised by Pavol NávratWith the coming era of semantic web, large, structured and linked datasets are becoming common. Unfortunately, current search engines mostly see web only as a graph of pages linked together by hyperlinks, thus becoming insufficient for users for searching in such new, structured and multidimensional data. When dealing with multidimensional data, identifying relations and attributes that are important for users to achieve their searching goals becomes crutial. Furthermore every user, can have different priorities, different goals which can even change in time.
One of the goals of this work is the extension of existing graph algorithms for multidimensional data, where the usage of tensor algebra and multigraphs can be useful, in contrast with currently preferred matrix algebra. Such extension of graph algorithms would be able to increase relevance and quality of search, and even enable new quality of query formulations.
Evaluation of relevance and quality of search can be done gathering implicit feedback (e.g. quality can be measured just by monitoring user interactions with the system). Another goal of this work is the exploitation of gathered (implicit or explicit) feedback from users to not only evaluate the underlying system, but also to analyse users behaviour thus opening possibilities for adaptation and personalization.
The main goal of this work is the usage of implicit feedback in search engines dealing with large multidimensional data, to improve search result quality and relevance of results.
-
Virtual Communities Identification for Adaptive Web Systems
Jozef Tomek
master study, supervised by Michal BarlaWith constantly increasing amount of information available on the internet, searching for relevant information is becoming bigger problem every day. Even though the current search engines are still fairly effective tools in the hands of an expert, an ordinary user is often flooded with results he is not interested in. That’s why they are becoming insufficient for vast majority of the still increasing number of internet users, what causes these search engines to be less usable.
One of the possible solutions of this problem is personalization of these systems, an approach that receives a lot of research attention during the last couple of years. What lurks behind this term is basically an effort to adjust the behaviour of the system to the individual needs of the particular user.
Human is a social being by the nature, so he tries to integrate himself into the community of other people he shares some common attribute, interest or attitude with. The world of the internet is no exception. People belonging to an internet community may be characterized by the same information interests. They search for and collect the same type and quality of information while browsing the web environment. Concerning this fact these two questions arise: how to identify these communities and how to assign a particular user to a particular community?
The objective of my diploma thesis is to analyse existing approaches in virtual communities identification on the web based on observing and analyzing user behavior. Especially, focusing on those that are applicable in real-time, thus the approaches that adjust user model after every user interaction. The main goal is to design a method that can perform communities identification real-time, together with considering already existing user models. Later to test the proposed method on real world scenario using the test data that represent real users’ interactions with the web space. These test data will be collected by adaptive proxy server, which is being developed on the faculty. The outcome of this work will be a communities model extracted from the input data set and a plugin for stated adaptive proxy server, which will perform application of the proposed method in real-time fashion.
-
Socially-Intelligent Tutoring and Collaboration
Jozef Tvarožek
doctoral study, supervised by Mária BielikováMotivation is not easy to maintain in computer-supported learning systems. One way to motivate students and improve learning is by attending to their emotional and affective states. Another way is to augment learning with collaborative and social experience. In collaboration, however, just placing students into a group does not guarantee success. Friends are more supportive and critical than non-friends, and were found to provide a better collaborative learning experience.
In our project, we are interested in how socializing the process of learning can improve motivation and learning, and devise computational models and methods to realize this concept. For this, we are building a prototype learning system that adds socially intelligent tutoring to our previous work which is a typical pseudo-tutor assessment system enhanced with free-text answering, and on-the-fly question generation and adaptive selection. In evaluation of our prototype, we are ultimately interested in how does the addition of an socially intelligent tutor, the tutoring friend, affect students’ on-class motivation and off-class system use. Additionally, we want to investigate the effect of an earlier anonymous collaboration between students that, in case of mutually positive evaluations, is transformed into an acquaintance by the tutoring friend, thus allowing the particular students a possible future encounter.
To endow the computer tutor with at least the appearance of human-level social intelligence, we tackle some of the hardest problems in artificial intelligence such as scaling of knowledge-based inferencing, temporal and spatial knowledge representation and reasoning, and case-based reasoning. The tutoring friend extracts instances of student’s social behavior such as past events the student attended in real life, future plans and opinions on interesting topics, and peer evaluations and group outcomes of collaborative activities performed by the student in the social learning system. The challenge is to gather descriptions of student’s events, plans and opinions during the off-task (socializing) dialogues with the tutor, and for this we employ a slot-filling dialogue manager that extracts (from student’s utterances) relevant attributes such as duration, location, and other participants.
-
Intuitive Exploratory Search
Michal Tvarožek
doctoral study, supervised by Mária BielikováExploratory search is one of the current approaches to information retrieval and content navigation in information spaces such as the Web or the Semantic Web. Exploratory search also signifies a shift in search and navigation approaches from traditional “closed” fact retrieval tasks towards more open ended tasks where users do not know beforehand what it is they actually seek. Typical examples of exploratory search include learning, exploration of an information space and the understanding of its structure, or analysis, comparison and forecasting.
The aim of our research is the extension an enhancement of exploratory search approaches with support for personalized browsing of an information space using an enhanced faceted browser. We focus on search, visualization and user interaction with structured information spaces described via ontologies. We extend classical faceted browsers with:
- dynamic facet generation using the structure of the information space (metadata),
- automatic adaptation of facet ordering and visualization to user preferences,
- dynamic generation of both textual and graphical views of the information space based on estimated user preferences,
- integration of keyword-based, view-based and content-based search approaches,
- support for collaboration and evaluation of users’ social relationships.
We evaluate our approach by conducting a user study in the digital library domain using heterogeneous content – digital images, publications and student projects. The proposed approach allows users to browse and search in arbitrary (structured) information spaces represented via ontologies (e.g., in OWL). We see several opportunities for the integration of our method with other approaches, mostly for input acquisition and information organization (e.g., classification or clustering). The integration with approaches for discovery of users’ social networks, the acquisition and maintenance of user models, and the integration with advanced data mining and visualization approaches appears of great interest.
-
Tax Fraud Detection with Relational Classifier
Peter Vojtek
doctoral study, supervised by Mária Bieliková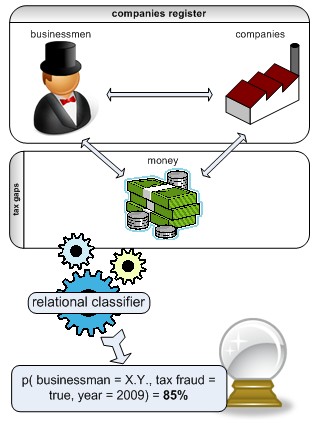
-
Searching Similarities and Clustering
Dušan Zeleník
master study, supervised by Mária BielikováWorking with information often requires prior preprocessing. To navigate in the large amount of data it is necessary to manually, or automatically prepare it. Speaking about for example searching, besides common full text approach we start to use recommendations to find our interests. Making up these recommendations could be based on user’s behaviour, and also searching for similarities of information. Problem which I decided to solve is discovering and processing of dynamic relations between objects. It comprises a framework creation where objects could be inserted, or removed, while relations and similarities can be retrieved for objects and their authors in real time. Similarities can be used to create groups of objects. These groups or clusters, are optimally divided focusing on similarities and sizes, they are evolving in time. Considered is overlapping of the clusters, what simply means that one object can be included in more groups. Dividing should sort a hyperspace of objects, providing simpler and faster access while searching.
I am analysing algorithms and trying to find insufficiency of them to bring up to date solution, which will be able to find more relevant attributes, relations between them, what helps to reduce hyperspace. Applying on specific domain it is possible to experimentally verify abilities of the dynamic clustering method. Appropriate domain could be texts of articles, but more daring is domain of pictures or music search by query made by user. By query in these cases I understand sketch or sound record directly from the user.
In these domains I suggest to make up kind of supporting taxonomy in the form of social game. Point is to make a game similar to charade game, which makes visual or audio representation of words, what helps to find a set usable for similarity search. This approach starts as way of support but with increasing of quantity and quality, searching in groups of real object would be incrementally replaced by search in groups of user provided inputs.